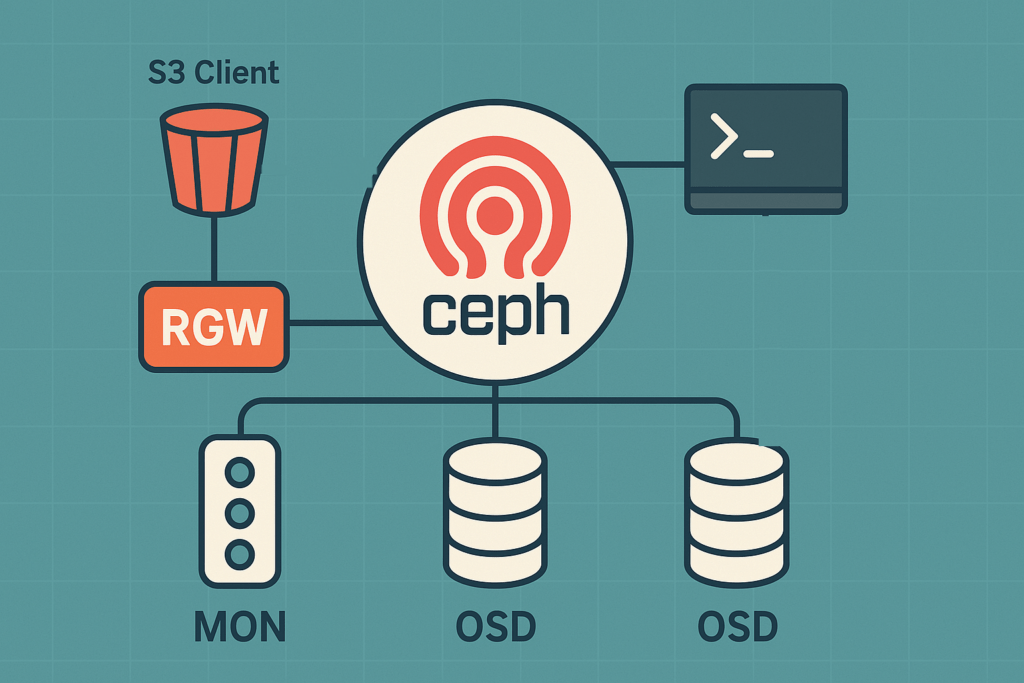
Ceph — ذخیرهسازی توزیعشدهٔ مقیاسساز
یک کلاستر واحد برای Object، Block و File؛ مقاوم در برابر خطا، افقی مقیاسپذیر، مناسب بارهای Cloud-Native و Enterprise.
RADOS — قلب قابلاعتماد Ceph
لایهٔ ذخیرهسازی توزیعشده با CRUSH برای توزیع یکنواخت دادهها، تحمل خطا و مقیاسپذیری افقی. پشتیبانی از Replication و Erasure Coding.
- CRUSH Placement & Failure Domains
- Replication 2/3 یا Erasure Coding برای بهرهوری فضا
- Self-Healing و Rebalancing خودکار

RBD — بلاک استوریج برای VM/DB
ولومهای بلاکی با Snapshot/Clone و یکپارچگی با KVM/Libvirt و Kubernetes (Rook CSI).
- Thin-Provisioning، Snapshot/Clone
- یکپارچه با OpenStack Cinder، Proxmox، K8s
- High IOPS برای دیتابیسها و VMها
CephFS — فایلسیستم توزیعشده
مناسب پردازش رسانه، محیطهای اشتراکی و دیتا پلتفرمها با قابلیت Namespace و Quota.
- Metadata Server های مقیاسپذیر
- Snapshot/Quota و چند Subvolume
- Driver برای Kubernetes (CSI)
RGW — آبجکت استوریج سازگار با S3
سازگار با S3/Swift برای اپهای ابری، آرشیو، بکاپ و تحلیل داده.
- Multi-Site، Versioning، Lifecycle
- Bucket Quota، دسترسی امضاشده، سیاستها
- سازگار با ابزارهای اکوسیستم S3
Ceph برای چه کارهایی مناسب است؟
ابر خصوصی و مجازیسازی
زیرساخت OpenStack/Proxmox با RBD برای VM و دیتابیسهای پرتراکنش.
Kubernetes-Native Storage
Provisioner های Rook/CSI برای بلاک، فایل و آبجکت—در یک کلاستر واحد.
آرشیو و بکاپ اقتصادی
RGW با Versioning/Lifecycle برای ذخیرهسازی سرد و نگهداری بلندمدت.
تحلیل داده و رسانه
CephFS/Obj برای پایپلاینهای رسانهای، ML و پردازش انبوه.
TCO & SLA — مهندسی هزینه و دسترسپذیری
مدلهای حفاظت
- Replication ×3: سادگی و ریکاوری سریع، هزینهٔ ظرفیت بالاتر
- Erasure Coding (k+m): بهرهوری ظرفیت بهتر، نیازمند CPU و Latency بیشتر
- Failure Domain: میزبان/رک/آویلبلیتیزون
SLA پیشنهادی
- 99.95% برای سرویسهای حیاتی (Multi-AZ + Mon quorum)
- RTO: <15 دقیقه | RPO: صفر (Replication) / نزدیک صفر (EC)
- پایش با Prometheus/Grafana + هشداردهی Alertmanager
سؤالات متداول Ceph
پاسخ کوتاه و فنی برای تصمیمگیری سریعتر.